Appearance
🤖 DataAgent:DVA
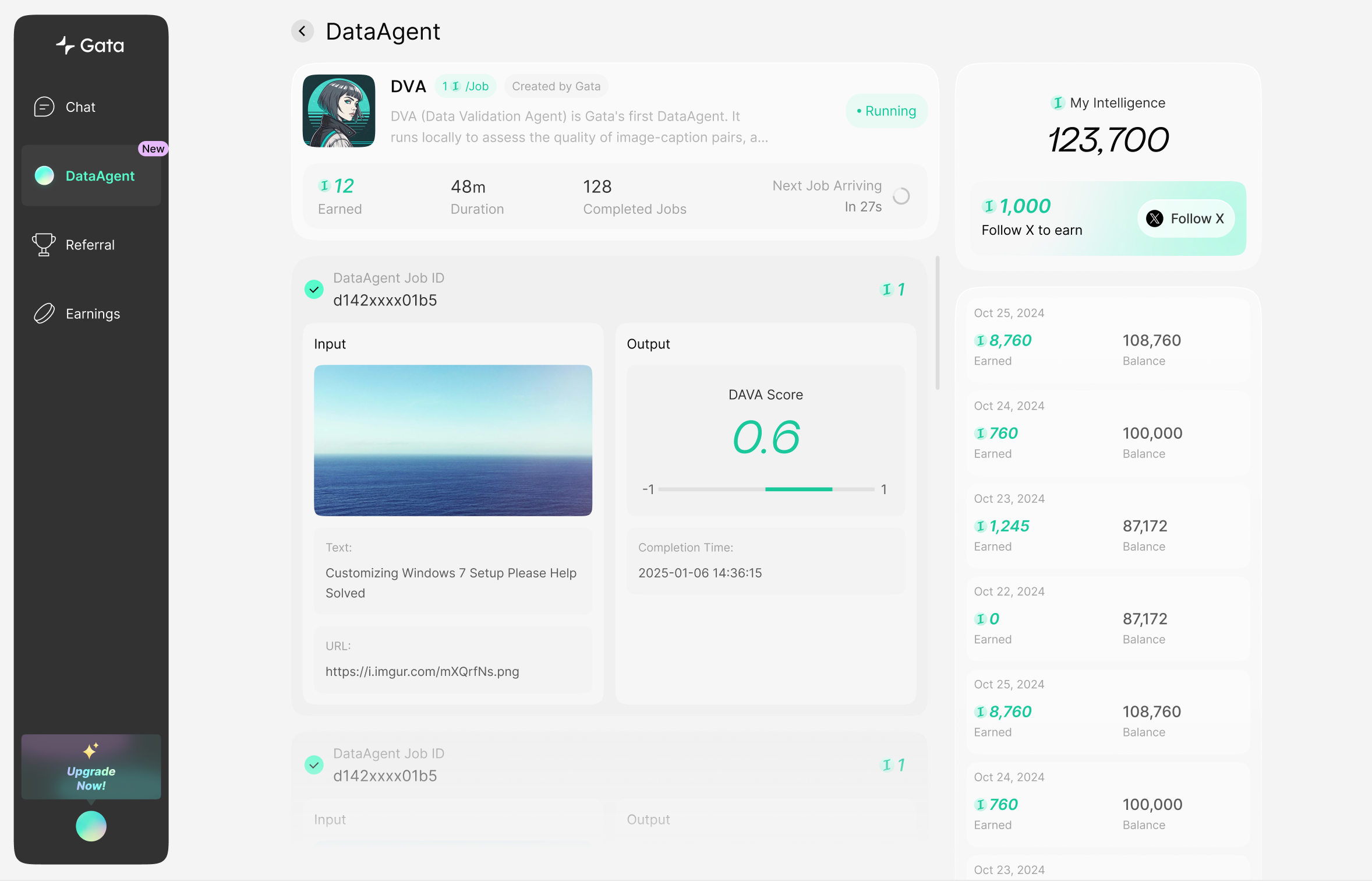 Gata DataAgent Platform
Gata DataAgent Platform
1. Gata DataAgent Platform
Gata is building the DataAgent Platform, enabling individuals to run various DataAgents that automatically generate cutting-edgee data and earn passive rewards.
Key features include:
- Automated AI Data Generation: Each DataAgent is designed to generate a specific type of cutting-edge, valuable AI data with minimal human effort, automating traditionally labor-intensive data labeling processes.
- Passive Rewards: Users earn rewards effortlessly as their DataAgents continuously contribute valuable, high-quality data.
Why DataAgent Platform:
- Shift from data as human labeling to data as a technology: Cutting-edge advancements in AI are increasingly dependent not merely on the availability of data, but on data innovations that can more effectviely advance AI. The reality is that we are rapidly exhausting both publicly available data and the capacity of highly skilled human labelers to directly annotate data for AI training.
- Accelerated AI Research-to-Data Production: The DataAgent platform facilitates the rapid translation of data innovations into large-scale data productions. By deploying data innovations as DataAgents and leveraging token-based incentives, we can mobilize individuals to directly crowdsource large-scale, high-quality datasets, such as synthetic data, human-AI copilot data, and other innovative data sources.
2. DVA DataAgent
DVA (Data Validation Agent) is Gata's first DataAgent. It runs locally to assess the quality of image-caption pairs from the whole internet, assigning a score between -1 and 1. DVA scores help select the highest-quality image-caption data, which are then used to train various vision-language AIs, such as Stable Diffusion, DALL-E, and GPT-4o.
3. Motivation
Internet-scale image-caption datasets, such as LAION and DataComp, underpin the pre-training of all vision-language AIs. These datasets, comprising tens of billions of image-caption pairs scraped from the internet, power text-to-image generative AI models like Stable Diffusion and DALL-E, as well as vision-language models like GPT-4V and GPT-4o.However, the AI industry faces two major challenges with internet-scale image-caption datasets:
- Exhaustion of Publicly Accessible Data: Most publicly available image-caption data has already been utilized.
- Noisy Captions: Captions derived from web scraping often fail to accurately represent the corresponding images.
Both academia and industry have explored two key approaches to address these challenges:
- Filtering: By evaluating the quality of image-caption pairs and assigning scores, high-quality subsets can be filtered for better training, as demonstrated in Apple's recent work.
- Synthetic Caption Generation: Vision-language models can be used to generate more accurate captions, significantly enhancing dataset quality, another approach explored by Apple.
DVA: The First DataAgent for Image-Caption Data
DVA evaluates the quality of image-caption pairs from across the internet and assigns scores ranging from -1 to 1. It is based on the Data Filtering Networks. These scores enable the selection of the highest-quality data, exemplifying the filtering approach.
Our Goal
We aim to develop a comprehensive suite of DataAgents that not only assess image-caption quality but also generate more accurate synthetic captions. By iteratively evaluating and improving the quality of these synthetic captions, we aim to create a drastically improved and verified Internet-scale image-caption dataset. This enhanced dataset will significantly advance vision-language AI, unlocking new opportunities for innovation in the field.
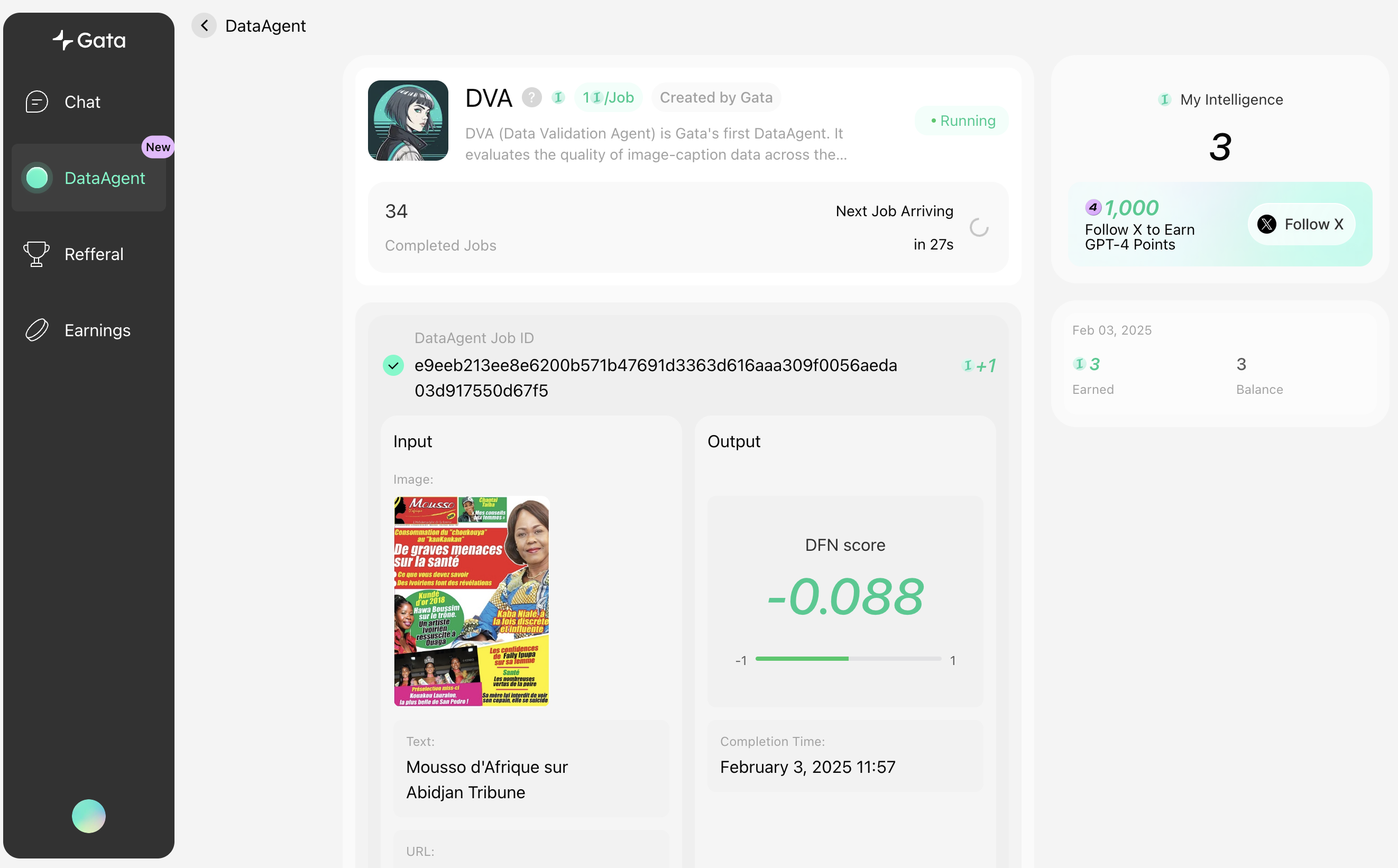 When running the DVA DataAgent, its inputs and outputs are displayed in real-time, ensuring transparency.
When running the DVA DataAgent, its inputs and outputs are displayed in real-time, ensuring transparency.